

Artificial intelligence systems are steadily growing more advanced. For humanity, they promise unprecedented problem-solving capabilities across various domains and sectors, be it revolutionizing healthcare, finding climate solutions, or myriad other wicked problems.
Modern, generative AI's impressive versatility fundamentally relies on pre-training, which is a resource intensive stage where models internalize vast datasets consisting of billions of tokens of text, images, audio, and video to master tasks like translation, image generation, and reasoning (Brown et al., 2020; Beaumont et al., 2022; Cheng et al., 2024).
However, the creative works essential for AI pre-training are increasingly harvested without adequate transparency, consent, or compensation, creating a paradox that threatens both AI innovation and human creativity. The notion that this practice is unsustainable is exemplified by recent high-profile legal cases. For example:

Graphic by Author
The New York Times filed a lawsuit against OpenAI for unauthorized ingestion of paywalled articles (Brittain, 2025). In March 2025, a federal judge advanced The Times' lawsuit, allowing its core copyright infringement claims to proceed. This is a significant development that could potentially result in billions in damages and force OpenAI to rebuild its datasets using only authorized content.
Complexly (the production company of Hank and John Green) discovered unauthorized scraping, or the automated extraction of data from their websites and videos into AI datasets without consent or compensation (Gilbertson & Reisner, 2024). Complexly’s only recourse was a very slow and expensive litigation, because YouTube’s Terms of Service governs creators and not unknown scrapers.
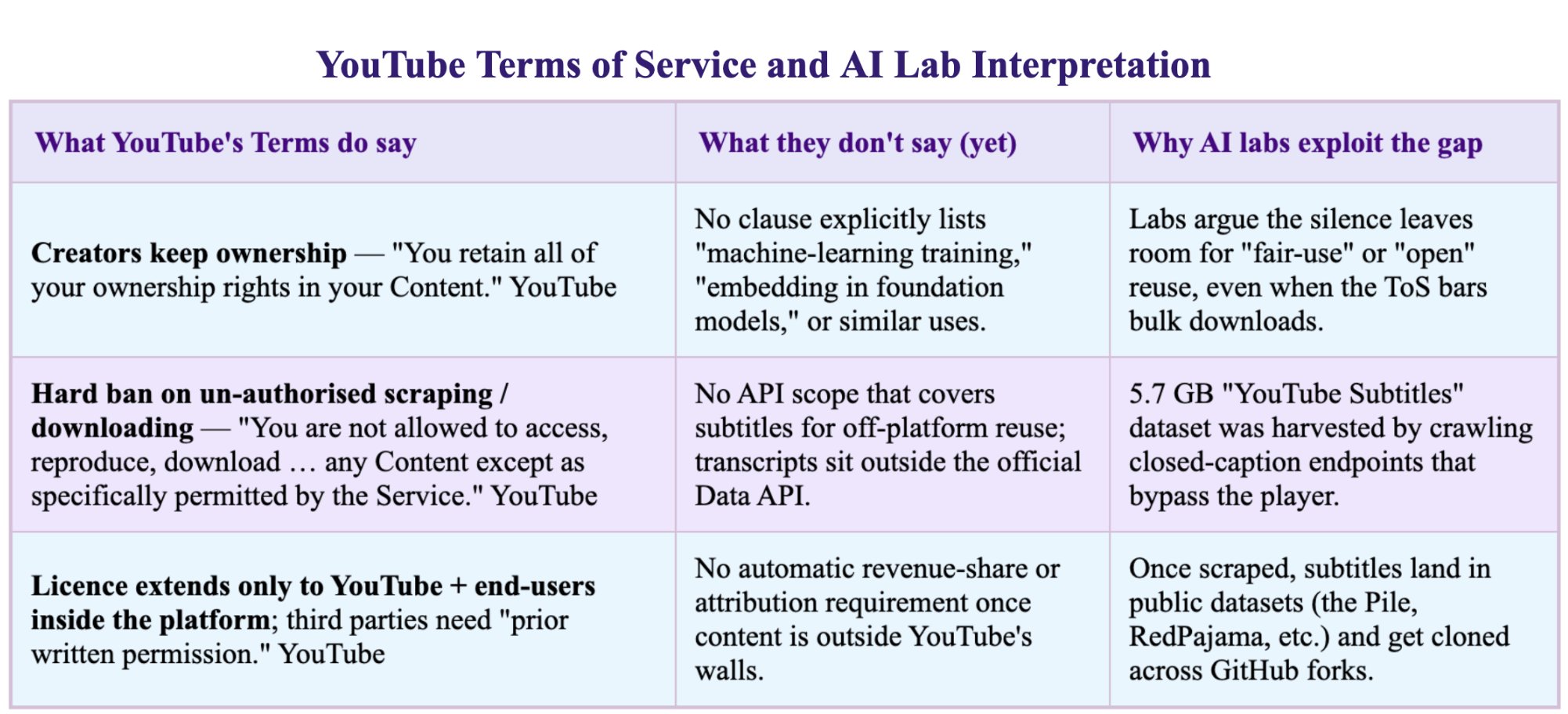
Graphic by Author
The issues at the core of many of the existing lawsuits stem from a lack of transparency. Generative AI training sets are typically opaque, treated as monolithic collections lacking traceability to original sources, creating resentment amongst artists, writers, other creators etc. With that, there is a risk that creators may withdraw their content, which would reduce data quality and diversity (Longpre et al., 2024).
This deteriorating data ecosystem risks model collapse, where AI models are forced to rely increasingly on synthetic or low-quality content, which leads to amplified hallucinations and homogenized outputs.
Creating a Sustainable AI Pre-Training Framework
Proper consent, attribution, and compensation would help remedy these issues and help the industry maintain a critical flow of authentic human creativity. An ideal solution would result in the preservation of high quality data and the creation cycle that is essential for continued AI advancement.
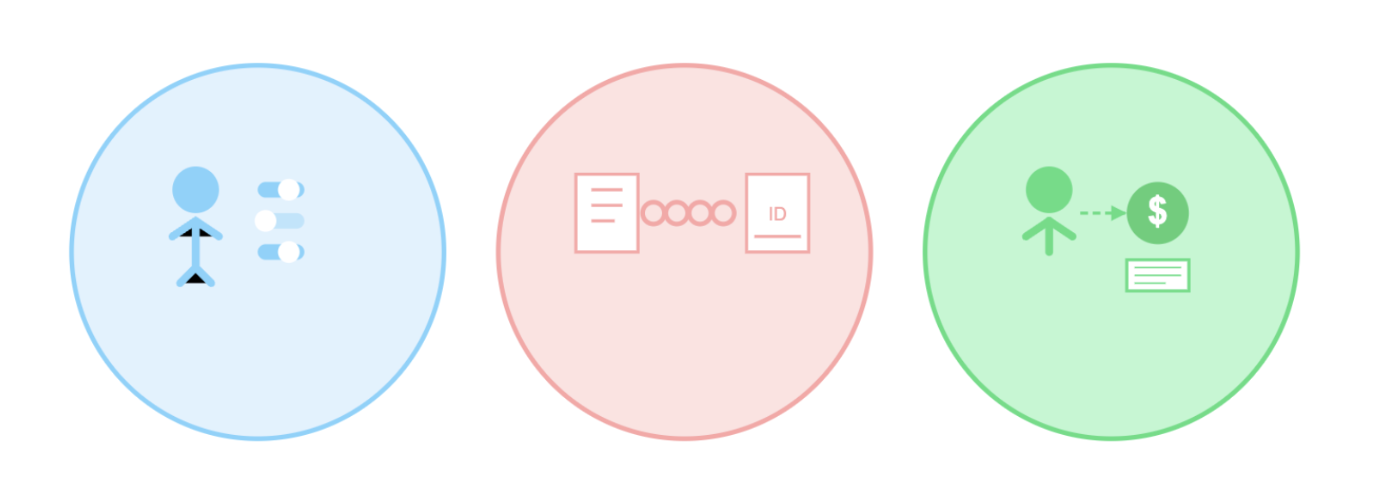
As such, to resolve this issue, I am proposing a sustainable AI pre-training framework that is built upon three interconnected pillars: dynamic consent, transparent attribution, and fair compensation.
Graphic by Author
Dynamic Consent
Dynamic consent provides creators granular control over if and how their content is used in AI training
Rather than binary permission, creators (including writers, musicians, artists, etc.) could specify nuanced permissions, like usage in particular AI models or under specific compensation terms
This flexibility would restore creator agency and would enable ongoing adjustments to permissions over time
Transparent Attribution
Transparent attribution involves embedding metadata to track content provenance throughout the AI lifecycle
Attribution chains enable AI-generated outputs to directly reference original sources to help with recognition and accountability
Such provenance tracking would reduce hallucinations in models by grounding outputs in verifiable sources
It would also ensure that a creator’s contributions are explicitly acknowledged
Fair Compensation
To practically and equitably compensate creators at scale, I propose three economic mechanisms:
Collective Licensing Pools
AI companies should contribute to centralized pools, analogous to music royalty systems, from which creators will receive proportional compensation based on usage of their content (Vincent, 2022).
2. Subscription Models
AI developers can subscribe to curated datasets to give creators predictable and usage based revenue streams, similar to some existing licensing agreements between OpenAI and media organizations (Mauran, 2024).
3. Levy Systems
AI providers pay levies based on their revenue or computational resources used for training and create a fund to be distributed among creators whose works contributed to the models (Pasquale & Sun, 2024)
Initial implementation could pose some challenges, such as infrastructure investments for managing consent, attribution, and compensation. However, the long-term benefits would substantially outweigh these costs. A transparent and standardized framework would stabilize the human content ecosystem, reduce litigation risks, and foster innovation as the framework would help clarify data rights and usage conditions.
Standardized consent and attribution protocols also would significantly streamline AI data pipelines, inspired by open-source licensing practices. These would facilitate clear and automated compliance, improving research collaboration and reducing legal uncertainty (Benhamou & Dulong de Rosnay, 2023).
Dynamic pricing would refine compensation by aligning remuneration with data quality and impact. Utilizing mechanisms like Data Shapley values would make sure that creators are rewarded proportionately to their content's value and usage, which would play a key role in incentivizing high quality content production tailored for AI training (Wang et al., 2025).
Secondary benefits of this framework extend beyond monetary compensation as well.
Visibility: Transparent attribution would help discoveries of creators and increase recognition
Democratized Participation: The standardized systems would let diverse creators of all sizes to participate in AI ecosystems
Strengthened Creative Markets: Sustainable revenue streams would support the continued production of high-quality content
Improved Model Quality: Attributed data would reduce hallucination by providing verifiable provenance
Technical feasibility is ambitious but certainly attainable and is supported by advancements in metadata tracking, machine unlearning, and identity verification technologies. Gradual implementation, beginning with coarse grained attribution and progressively refining consent and compensation mechanisms would also present a pragmatic approach to go forth with.
The current asymmetric relationship between AI developers and creators is
economically unsustainable.
With no solution we risk entering a cycle where we discredit the world’s creators and diminish creator incentives, leading to less original content, poorer training data, and degraded AI capabilities: outcomes which serve neither creators nor technology companies nor society at large.
Establishing a transparent, consent-driven AI pretraining framework is essential for AI's long-term sustainability. The framework discussed here is one that will realign incentives, restore creator agency, and standardize data practices, leading to a balanced, ethical, and productive partnership between AI developers and human creativity. This will preserve innovation and ensure equitable benefits, and also reinforce trust in AI as a foundational technology for humanity's collective future.
The urgency of implementing such a framework cannot be overstated. As AI models grow more capable and pervasive, the window for establishing ethical norms around training data narrows. Acting now will ensure creators' rights are taken care of, help us maintain innovation, and allow us to build an AI ecosystem together that remains vibrant, diverse, and sustainable for generations to come.
-
Beaumont, R. "5B: A New Era of Open Large-Scale Multi-Modal Datasets." LAION, March 31, 2022. https://laion.ai/blog/laion-5b/.
Benhamou, Y., and M. Dulong de Rosnay. "Open Data Commons Licenses (ODCL): Licensing Personal and Non Personal Data Supporting the Commons and Privacy." SSRN Electronic Journal, December 2023. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4662511.
Brittain, B. "Meta Says Copying Books Was 'Fair Use' in Authors' AI Lawsuit." Reuters, March 25, 2025. https://www.reuters.com/legal/litigation/meta-says-copying-books-was-fair-use-authors-ai-lawsuit-2025-03-25/.
Brittain, B. "Judge Explains Order for New York Times in OpenAI Copyright Case." Reuters, April 4, 2025. https://www.reuters.com/legal/litigation/judge-explains-order-new-york-times-openai-copyright-case-2025-04-04/.
Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. "Language Models Are Few-Shot Learners." arXiv.org, July 22, 2020. https://arxiv.org/abs/2005.14165.
Cheng, Z., S. Leng, H. Zhang, Y. Xin, X. Li, G. Chen, Y. Zhu, W. Zhang, Z. Luo, D. Zhao, and L. Bing. "VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs." arXiv.org, October 30, 2024. https://arxiv.org/abs/2406.07476.
Gilbertson, Alex, and Aaron Reisner. "Apple, Nvidia, Anthropic Used Thousands of Swiped YouTube Videos to Train AI." Proof News, July 16, 2024. https://www.proofnews.org/apple-nvidia-anthropic-used-thousands-of-swiped-youtube-videos-to-train-ai/.
Longpre, Shayne, Ritik Mahari, Alex Chen, Nithya Obeng-Marnu, David Sileo, Will Brannon, Niklas Muennighoff, et al. "A Large-Scale Audit of Dataset Licensing and Attribution in AI." Nature Machine Intelligence 6, no. 5 (August 30, 2024). https://www.nature.com/articles/s42256-024-00878-8.
Mauran, Catherine. "All the Media Companies That Have Licensing Deals with OpenAI (So Far)." Mashable, June 21, 2024. https://mashable.com/article/all-the-media-companies-that-have-licensing-deals-with-openai-so-far.
Pasquale, Frank, and Honghao Sun. "Consent and Compensation: Resolving Generative AI's Copyright Crisis." Cornell Legal Studies Research Paper 26, no. 5 (May 1, 2024). https://virginialawreview.org/articles/consent-and-compensation-resolving-generative-ais-copyright-crisis/.
Vincent, James. "Shutterstock Will Start Selling AI-Generated Stock Imagery with Help from OpenAI." The Verge, October 25, 2022. https://www.theverge.com/2022/10/25/23422359/shutterstock-ai-generated-art-openai-dall-e-partnership-contributors-fund-reimbursement.
Wang, J. T., P. Mittal, D. Song, and R. Jia. "Data Shapley in One Training Run." ICLR 2025 Oral, January 22, 2025. https://openreview.net/forum?id=HD6bWcj87Y.