

Authors: Mikayla Dimick and Grace Puckett
This is Part 1 of a three-part series. Read Part 2, Mapping Movement: Network Mapping in the Dance Industry, here and Part 3, Observing Relationships Between Producers and Fandom through Digital Mapping, here.
With the digitization of our world, data has proven to be incredibly useful for arts and entertainment organizations in terms of decision-making and strategy formation. However, organizations can often be at a loss with how to collect data, how to format data visually, or how to use the data to achieve their goals. This three-part series will discuss data collection technologies, different ways to display collected data, and how the collected data can be used by institutions. What follows is a discussion/outline of two methods for gathering external data for internal use in arts and entertainment institutions: web scraping and data scraping.
These technologies are often used interchangeably, but there are key differences that set web scraping and data scraping apart. Each method of data collection uses contrasting collection techniques, data formatting, and varying levels of automation and analysis after data is collected.
Web Scraping
Web scraping is “the process whereby large sets of data are analyzed in order to find patterns, relationships, and trends that otherwise might be missed through more traditional analysis methods … to uncover shared similarities or groupings in web data that help gain insights for business decisions (import.io).” This makes web scraping a powerful tool that arts and entertainment institutions can incorporate into their methods for data analytics. It helps managers access information from various online sources to be viewed in one, central location. As such, web scraping can be used to help observe online communities or sources without using invasive tactics.
Understanding Web Scraping
There are a variety of ways to scrape websites, but the most common and practical form of scraping utilizes software that automatically scrapes large amounts of data from the web. These “specialized tools and techniques can be used to automate this process [data collection], by defining what sites to visit, what information to look for, and whether data extraction should stop once the end of a page has been reached, or whether to follow hyperlinks and repeat the process recursively. Automating web scraping also allows users to define whether the process should be run at regular intervals and capture changes in the data (Library Carpentry, 2019).”
Web scraping software uses two forms of technology to extract online data: web crawlers and web scrapers. Composed of artificial intelligence that seeks out information they are programmed to find, web crawlers typically use keywords or links that connect websites to one another. In contrast, web scrapers are tools that extract relevant data or information once identified by the crawler. Scrapers can also be programmed to collect and organize this information into formats that can be altered and accessed offline. This enables organizations to interact with, edit, and manipulate data within file formats such as .XLSX, .CSV, and, .JSON. (ScrapingHub)
Using Web Scraping
A distinct feature of web scraping is its automated nature of online data collection, fueled by artificial intelligence. Once parameters are set, the crawlers and scrapers will continuously refer back to established keywords and content information to seek out and collect data over designated periods of time. As a result, web scraping enables managers to test the functionality of one’s own online content, discover new information across online platforms, and compare/analyze data sourced from different websites (Velotio Technologies, 2019). This process is useful when looking at differences and similarities in data, changes in data over time through repeated scraping, and predicting trends that may translate from one source to another.
Data Scraping
Technically defined as “the construction of an agent to download, parse, and organize data from the web in an automated manner”(Baesens), data scraping works to utilize the processing power of computers to identify and pull massive amounts of information together. The process is time-efficient and effective for arts and entertainment managers, as the technology helps create comprehensive archives of data at incredible speeds. This allows for a central focus of resources on formatting and analyzing the data according to the needs of their organization.
Sound familiar? Though there are similarities, data scraping should not be confused for web scraping, as the outputs and handling of data by each are drastically different. Web scraping automatically looks for trends, patterns, and unique observations. Information gathered through data scraping, however, must be organized and sifted through by hand or other human intervention.
Understanding Data Scraping
Similar to how information is pulled together for the result page of a search engine, the process of data scraping identifies and aggregates together key pieces of information through the use of crawlers or simplified point-and-click systems. The ability to write in various programming languages, while helpful, isn’t required for the latter thanks to free simplified interfaces online that anyone can use. Platforms such as ParseHub and Visual Scraper allow users to indicate what data they are looking for and how each piece relates to the others, without needed to code any parameters. The type of data pulled can be anything, as long as it can be found on a website or within a website’s code. Pulling data through scraping, of course, is dependent on a website allowing information to be collected without gaining additional permissions from the site’s owner. As concerns about privacy grow and policies continue to be enacted, some websites have measures in place to prevent scraping. Should you use this method to aggregate data, know that you may come up against this and may need to pull data by hand.
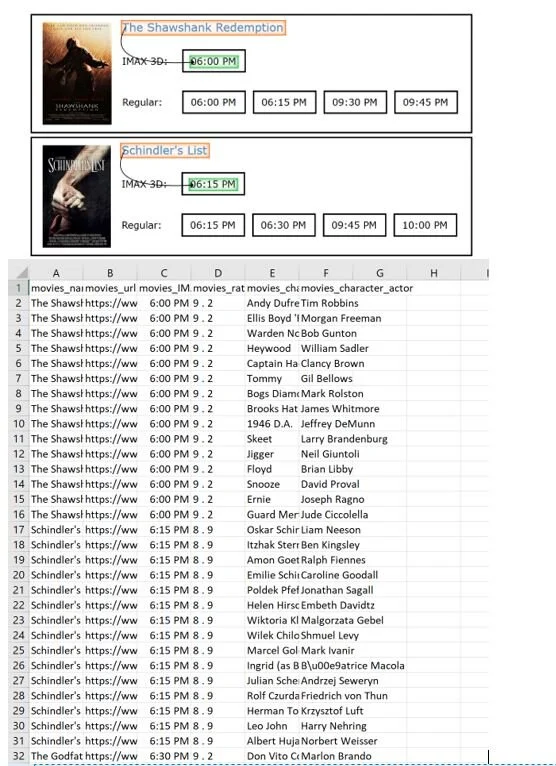
Image: An example of ParseHub’s point-and-click method to indicate relationships and the resulting spreadsheet with additional information. Source: Screenshot by Author of ParseHub’s introductory tutorial.
Using Data Scraping
Once all necessary data has been collected, researchers must find a way to critically consider the information that’s been pulled. Lists and excel spreadsheets are wonderful, but if you can’t visualize your data, that’s all it will ever be - just a bunch of meaningless or hard-to-decipher rows and columns. Data scraping provides a wonderful starting point from which to move into crafting network maps that transform relationships between data into observable entities.
As a result of the similarities between these two methods, it isn’t likely that an arts manager would use them in tandem. Rather, an arts manager should consider what kind of data they wish to gather, how much there might be, the purpose for doing so, and what they hope to do with said information. If you wish to look at data that potentially ranges into the hundreds of thousands, consider using web scraping for its automation and the ability to let it run without requiring constant checking. If the amount of data is closer to hundreds and is potentially feasible for an individual to handle, consider using data scraping for its friendliness to non-coders.
Each of these methods provide opportunities to deepen our study of data in ways that the arts have either avoided or been able to do in the past. CRM systems have been helping in that endeavor, but that information is limited to what we already have (though that is certainly not a bad thing in some cases). To learn more about how arts managers can use web scraping and data scraping in practical ways, check out Parts 2 and 3 of this series next week!